Tabla de contenidos
Requisitos previos para ejecutar el código
Antes de lanzarte a escribir el código, tienes que cumplir unos cuantos requisitos previos. Se trata de unos requisitos muy básicos, que pueden hacer más fácil y eficaz el uso de Python.
- Python: Tener instalada la última versión de Python sería una buena decisión. Puedes instalar cualquier IDE de Python para obtener los mejores resultados
- Noticias del sitio web/acceso a Internet: Dado que el código Python lee los principales titulares de tu sitio web favorito, debes asegurarte de que puedes acceder al sitio web mientras ejecutas este código
Todo el código está escrito en Jupyter Notebook, un popular IDE de Python para esta guía. Además, el sitio web de noticias de India Today está codificado dentro del código de ejemplo.
Para descargar Jupyter Notebook, puedes utilizarlo como parte del paquete anaconda, o descargar una versión independiente en tu sistema.
Descarga: Anaconda | Jupyter Notebook
Sin más preámbulos, vamos a profundizar en el código.
Escribir el código en Python
Para empezar, necesitas importar unas cuantas bibliotecas de Python, cada una de las cuales sirve para diferentes propósitos.
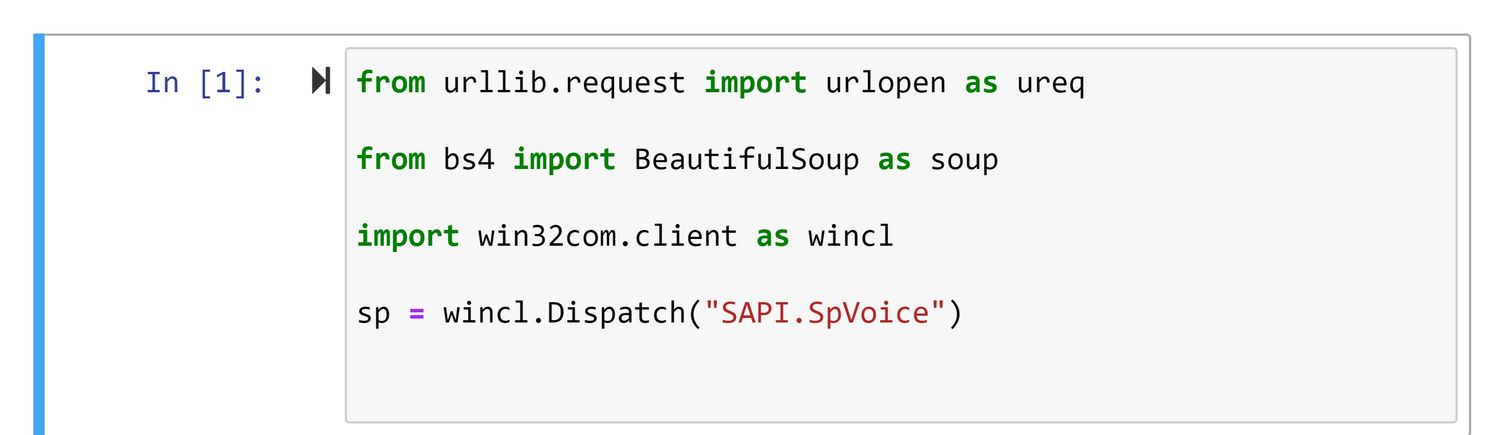
import win32com.client as wincl
from urllib.request import urlopen as ureq
from bs4 import BeautifulSoup as soupsp = wincl.Dispatch("SAPI.spVoice")Dónde:
- win32com.client Esta biblioteca interactúa con los dispositivos de Windows y ejecuta programas de Python sin problemas
- urllib.request Esta biblioteca maneja los valores de la URL del módulo de solicitud
- bs4 La biblioteca BS4 contiene la función Beautiful Soup, que raspa datos de sitios web utilizando Python
- sp = wincl.Dispatch(«SAPI.spVoice»): Activa los comandos de voz en Windows
Este código sólo funcionará en Windows, ya que llamarás a la biblioteca win32.com.client.
A continuación, tienes que definir la URL (enlace) del sitio web dentro del url que se almacena en la memoria de Python.
url = https://www.indiatoday.in/top-storiesCrea una nueva variable cliente para almacenar el comando de apertura de la URL.
client = ureq(url)
print(client)donde:
- cliente: Nueva variable
- ureq: Función Python importada de urllib.request, que abre la url almacenada

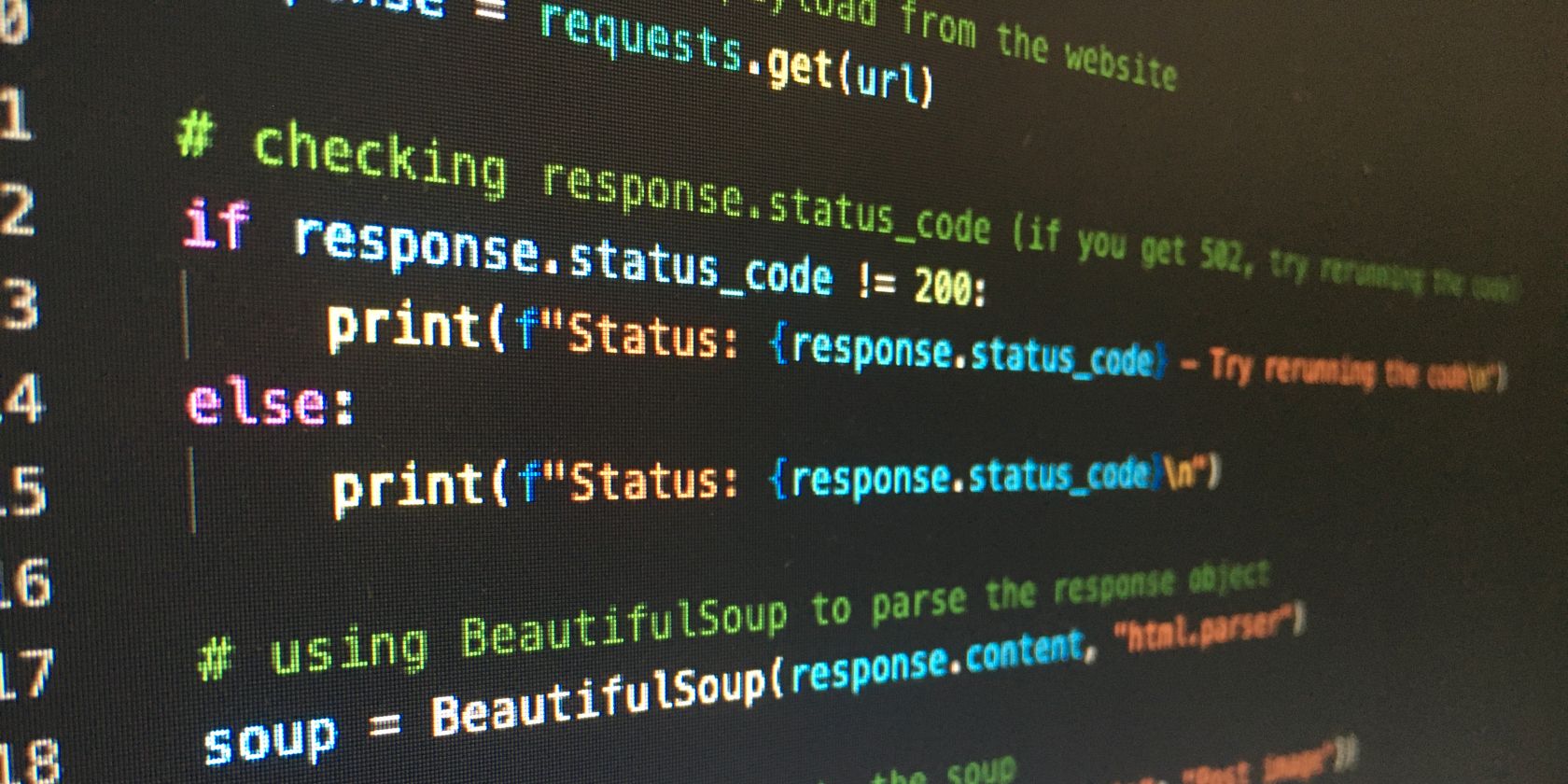
Ya que has abierto la URL en la memoria, es el momento de comprobar si el sitio web en cuestión permite conexiones no seguras a través de Python. Puedes imprimir la variable del cliente y comprobar el resultado.
Hay dos posibilidades con el comando print:
- HTTPError: Cuando un sitio web es seguro, no se puede raspar el contenido con Python

- Fragmento de código: Si se devuelve un fragmento de código después de ejecutar el sitio web, asume que puedes sacar fácilmente los titulares

Una vez que hayas definido la URL del sitio web de noticias dentro del comando URL, es el momento de importar el código HTML a una variable.
page_html = client.read()
print(page_html)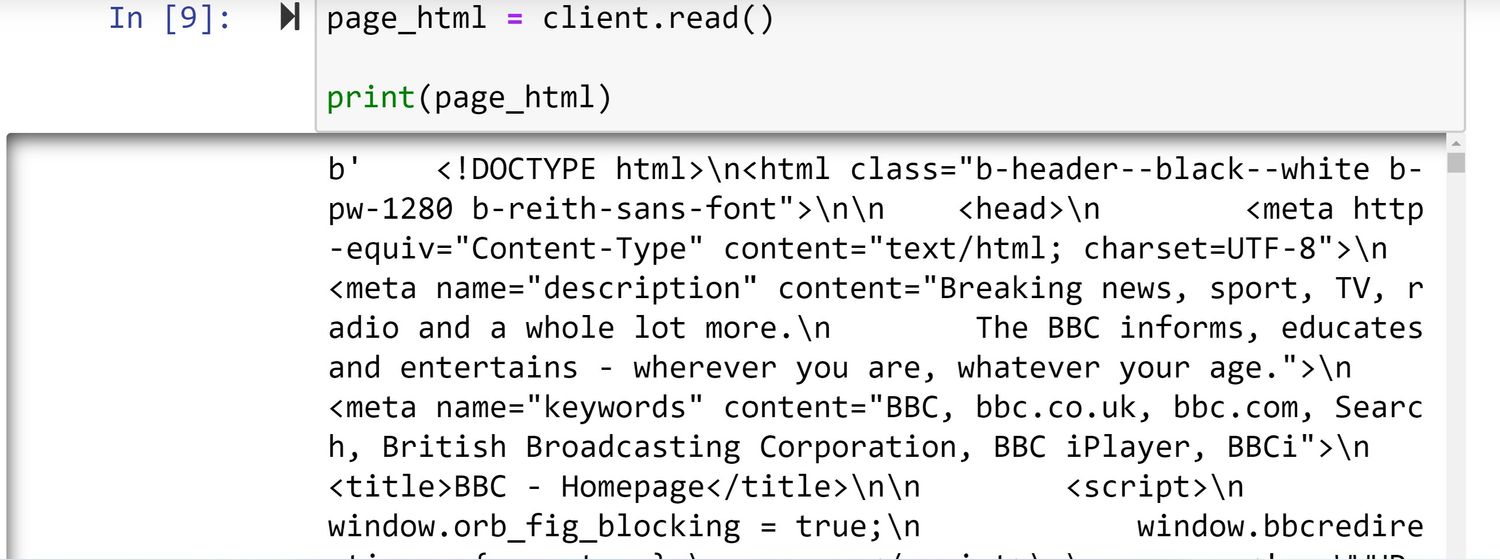
Debes imprimir el código HTML del sitio web importado a Python como paso de precaución. Incluso puedes hacer coincidir este código con el código del sitio web disponible en el Inspeccionar opción.
Antes de convertir el código, debes cerrar el sitio web de la memoria de Python utilizando el comando close.
client.close()Como tienes el código HTML importado en una variable de Python, necesitas convertirlo en un formato legible para Python para aplicar el encontrar y findall comandos para buscar palabras clave.
Puedes pasar el siguiente comando para convertir el código HTML:
page_soup = soup(page_html , "html.parser")Donde:
- página_sopa: Nueva variable
- sopa Alias para el módulo Sopa Bonita
- page_html: Variable que contiene el código HTML de la página web
- html_parser: Sintaxis por defecto para convertir el código HTML
Una vez que el código está listo para su uso, es el momento de examinar el código HTML del sitio web para empezar a buscar las palabras clave de los titulares.
Para ello, haz clic con el botón derecho del ratón en cualquier parte del sitio web y haz clic en Inspeccionar. Esto abrirá el código HTML del sitio web en cuestión.
En la ventana de código del sitio web, desplázate hasta localizar las etiquetas contenedoras que almacenan los titulares.
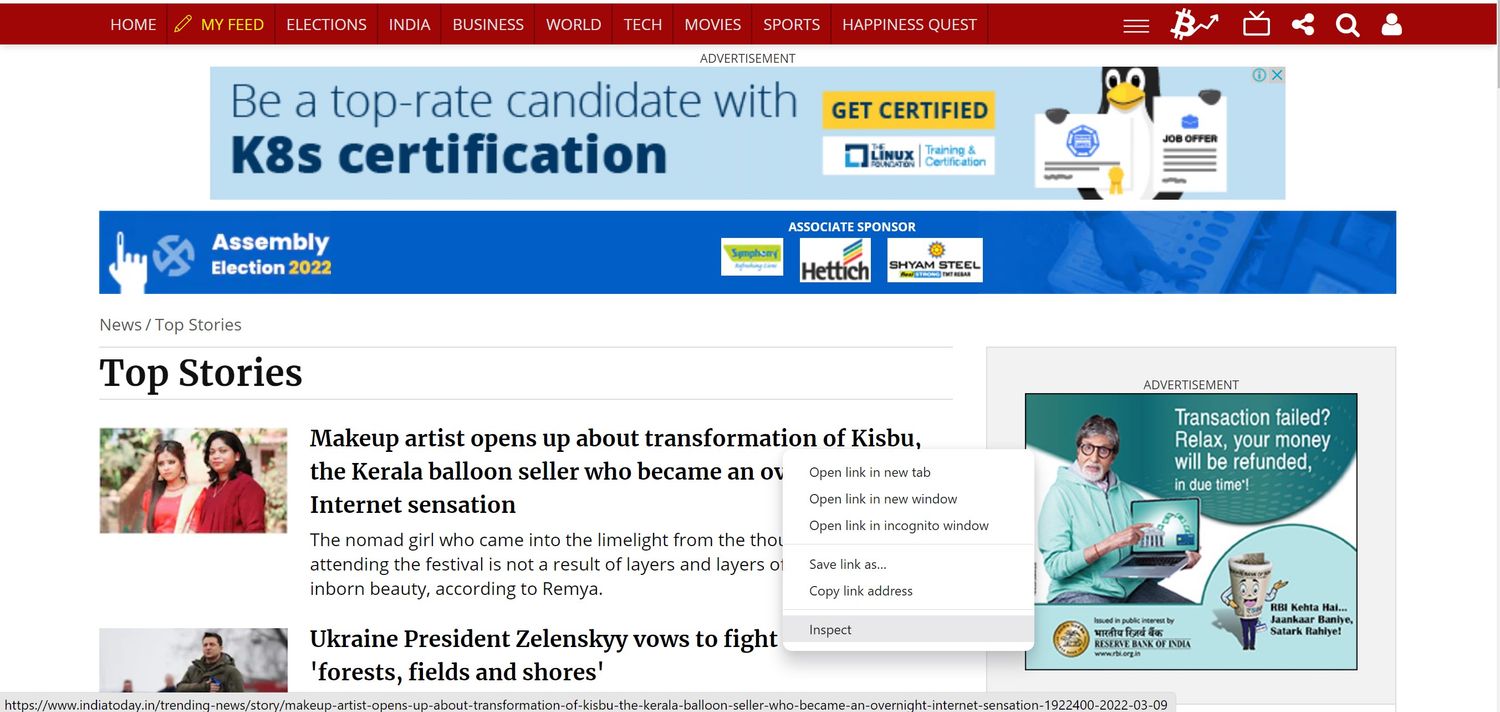
Están contenidas dentro de la etiqueta ver-contenido en el sitio web de India Today. Los contenedores de cada sitio web de noticias varían, pero deberías poder navegar por el código con relativa facilidad.
articles = page_soup.find("div" , { "class" : "view-content" })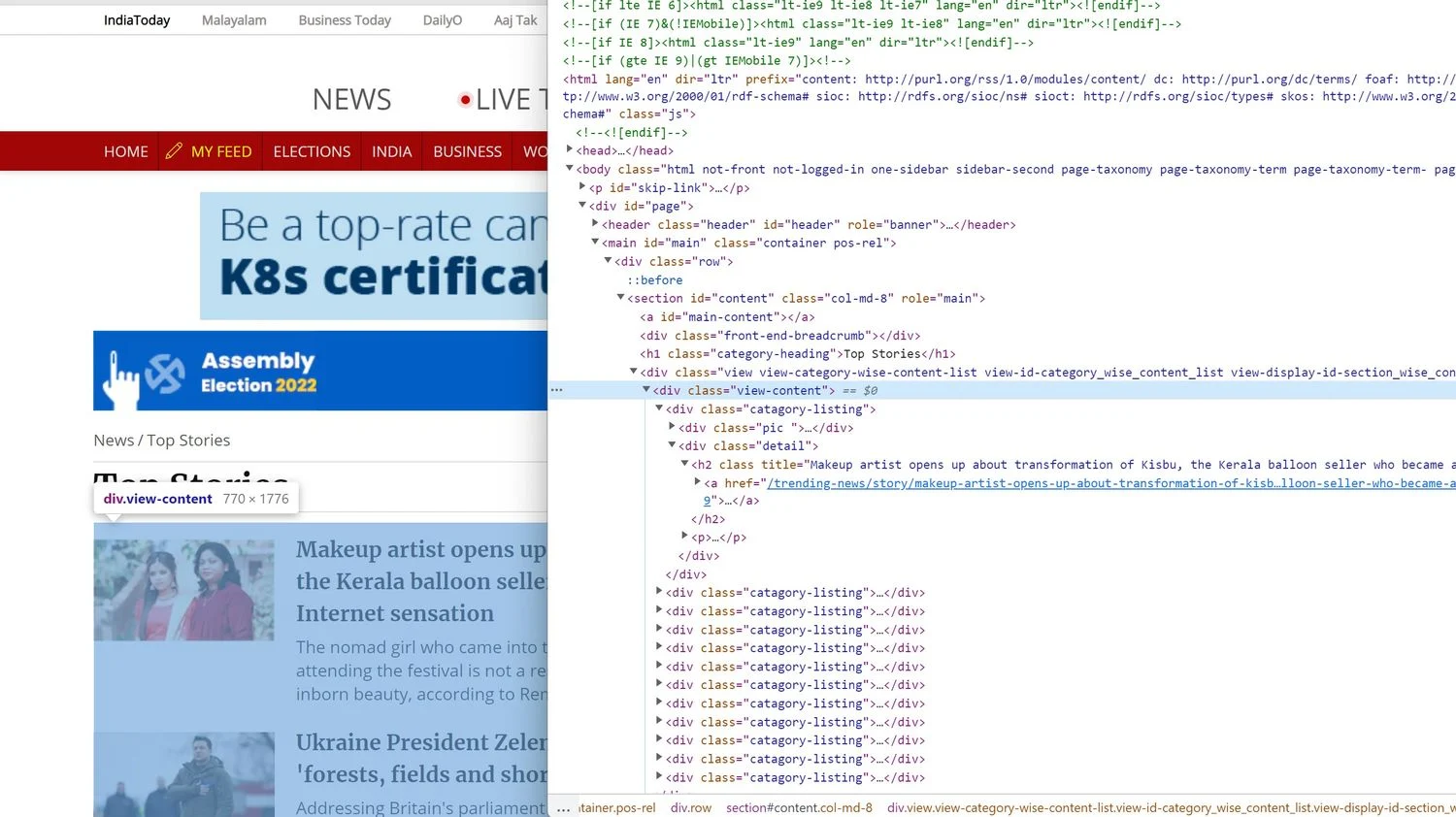
Por último, tienes que capturar las sub-etiquetas, que contienen los titulares principales que Python te leerá.
articles = articles.findAll("div" , {"class" : "catagory-listing"})
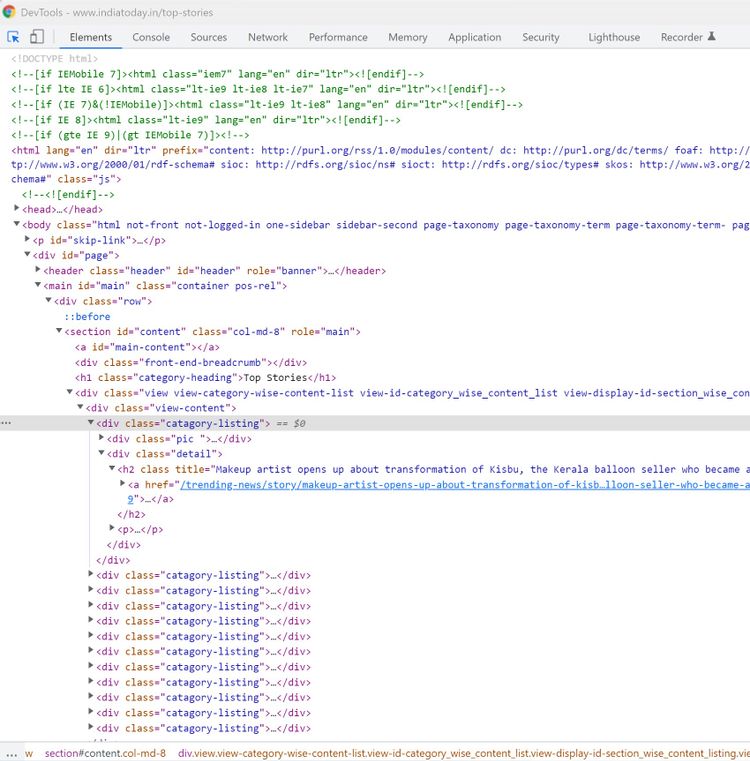
El contenedor view-content contendrá varios titulares, la envoltura exterior de tus titulares.
Para capturar las etiquetas H2 y los fragmentos que aparecen con cada titular, tienes que ejecutar un bucle.
i = 1
for x in articles:
title = x.find("h2").text
para = x.find("p").text
print(i , title , "
" , "
" , para , "
" , "
")
sp.Speak(title)
sp.Speak(para)
i=i+1Donde:
- i Nueva variable de contador, que se autoincrementará
- título: Nueva variable para guardar el titular (h2)
- para: Nueva variable para contener los párrafos asociados a cada H2
- imprimir: El título de la cabecera y el párrafo se imprimirán en la interfaz de Python
- sp.Speak(Título): Python leerá en voz alta cada título almacenado
- sp.Speak(para): Python leerá cada fragmento de párrafo almacenado
- i = i+1: Este comando autoincrementa el número de serie asociado a cada titular mostrado en la interfaz de Python
Utilizando el módulo «Beautiful Soup» de Python para leer tus noticias diarias
Cada vez que ejecutes el código, se descargarán nuevos titulares del sitio web de noticias antes de ser leídos en voz alta. Python ejecuta el código cada vez que ejecutas el conjunto de códigos, manteniéndote así actualizado con los cambios en el sitio web.
Los titulares más antiguos seguirán siendo mostrados y leídos por Python hasta que actualices y vuelvas a ejecutar el código.
Usar Python para leer tus titulares diarios es fácil
Python, como lenguaje de código abierto, ofrece una serie de herramientas -como Beautiful Soup, Selenium y otros frameworks- tanto para principiantes como para usuarios avanzados.
Si quieres recibir tus noticias diarias por voz, Python te lo pone fácil. Aprender este lenguaje en particular también puede ayudarte a convertirte en un mejor programador en todos los ámbitos.





